Droga do zostania biegłym i odnoszącym sukcesy programistą jest trudna, ale z pewnością możliwa do osiągnięcia. Struktury danych są podstawowym elementem, który każdy student programowania musi opanować, a prawdopodobnie już się nauczyłeś lub pracowałeś z niektórymi podstawowymi strukturami danych, takimi jak tablice lub listy.
Ankieterzy wolą zadawać pytania związane ze strukturami danych, więc jeśli przygotowujesz się do rozmowy o pracę, będziesz musiał odświeżyć swoją wiedzę o strukturach danych. Czytaj dalej, ponieważ wymieniamy najważniejsze struktury danych dla programistów i rozmów kwalifikacyjnych.
Listy połączone są jedną z najbardziej podstawowych struktur danych i często stanowią punkt wyjścia dla studentów na większości kursów dotyczących struktur danych. Listy połączone to liniowe struktury danych, które umożliwiają sekwencyjny dostęp do danych.
Elementy z połączonej listy są przechowywane w poszczególnych węzłach, które są połączone (połączone) za pomocą wskaźników. Możesz myśleć o połączonej liście jako o łańcuchu węzłów połączonych ze sobą różnymi wskaźnikami.
Związane z: Wprowadzenie do korzystania z list połączonych w Javie
Zanim przejdziemy do specyfiki różnych typów list połączonych, kluczowe jest zrozumienie struktury i implementacji poszczególnych węzłów. Każdy węzeł w połączonej liście ma co najmniej jeden wskaźnik (podwójnie połączone węzły listy mają dwa wskaźniki), który łączy go z następnym węzłem na liście i samym elementem danych.
Każda połączona lista ma węzeł główny i końcowy. Węzły listy z pojedynczym łączem mają tylko jeden wskaźnik, który wskazuje na następny węzeł w łańcuchu. Oprócz następnego wskaźnika, podwójnie połączone węzły listy mają inny wskaźnik, który wskazuje na poprzedni węzeł w łańcuchu.
Pytania do rozmowy kwalifikacyjnej związane z listami połączonymi zwykle dotyczą wstawiania, wyszukiwania lub usuwania określonego elementu. Wstawianie na połączonej liście zajmuje O(1) czas, ale usuwanie i wyszukiwanie w najgorszym przypadku może zająć O(n). Tak więc połączone listy nie są idealne.
2. Drzewo binarne
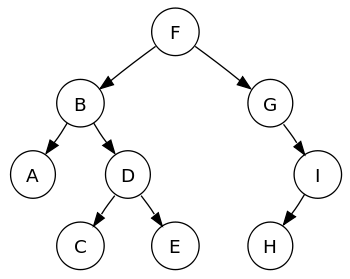
Drzewa binarne są najpopularniejszym podzbiorem struktury danych rodziny drzew; elementy w drzewie binarnym są ułożone hierarchicznie. Inne rodzaje drzew to AVL, czerwono-czarne, drzewa B itp. Węzły drzewa binarnego zawierają element danych i dwa wskaźniki do każdego węzła podrzędnego.
Każdy węzeł nadrzędny w drzewie binarnym może mieć maksymalnie dwa węzły potomne, a każdy węzeł potomny z kolei może być rodzicem dwóch węzłów.
Związane z: Przewodnik dla początkujących po drzewach binarnych
Drzewo wyszukiwania binarnego (BST) przechowuje dane w uporządkowanej kolejności, w której elementy o parze klucz-wartość mniejszej niż element nadrzędny węzeł są przechowywane po lewej stronie, a elementy z parą klucz-wartość większą niż węzeł nadrzędny są przechowywane na prawidłowy.
Drzewa binarne są często zadawane podczas wywiadów, więc jeśli przygotowujesz się do rozmowy, powinieneś wiedzieć, jak spłaszczyć drzewo binarne, wyszukać konkretny element i nie tylko.
3. Tabela haszowania
Tabele skrótów lub mapy skrótów to wysoce wydajna struktura danych, która przechowuje dane w formacie tablicy. Każdemu elementowi danych przypisywana jest unikalna wartość indeksu w tablicy mieszającej, co pozwala na sprawne wyszukiwanie i usuwanie.
Proces przypisywania lub mapowania kluczy w mapie mieszania nazywa się haszowaniem. Im bardziej wydajna funkcja mieszająca, tym lepsza wydajność samej tablicy mieszającej.
Każda tabela mieszająca przechowuje elementy danych w parze wartość-indeks.
Gdzie value to dane, które mają być przechowywane, a index to unikalna liczba całkowita używana do mapowania elementu do tabeli. Funkcje mieszające mogą być bardzo złożone lub bardzo proste, w zależności od wymaganej wydajności tablicy mieszającej i sposobu rozwiązywania kolizji.
Kolizje często powstają, gdy funkcja mieszająca tworzy to samo mapowanie dla różnych elementów; Kolizje map mieszających można rozwiązać na różne sposoby, używając otwartego adresowania lub tworzenia łańcuchów.
Tabele skrótów lub mapy skrótów mają wiele różnych zastosowań, w tym kryptografię. Są to struktury danych pierwszego wyboru, gdy wymagane jest wstawianie lub wyszukiwanie w stałym czasie O(1).
4. Półki na książki
Stosy są jedną z prostszych struktur danych i są dość łatwe do opanowania. Struktura danych stosu jest zasadniczo dowolnym rzeczywistym stosem (pomyśl o stosie pudełek lub płyt) i działa w sposób LIFO (ostatnie weszło, pierwsze wyszło).
Właściwość LIFO stosów oznacza, że ostatnio wstawiony element będzie dostępny jako pierwszy. Nie możesz uzyskać dostępu do elementów znajdujących się poniżej górnego elementu w stosie bez usunięcia elementów znajdujących się nad nim.
Stosy mają dwie podstawowe operacje — push i pop. Push służy do wstawiania elementu do stosu, a pop usuwa najwyższy element ze stosu.
Mają też wiele przydatnych aplikacji, więc bardzo często ankieterzy zadają pytania związane ze stosami. Umiejętność odwrócenia stosu i oceny wyrażeń jest dość istotna.
5. Kolejki
Kolejki są podobne do stosów, ale działają w sposób FIFO (pierwsze weszło, pierwsze wyszło), co oznacza, że masz dostęp do elementów wstawionych wcześniej. Strukturę danych kolejki można zwizualizować jako dowolną prawdziwą kolejkę, w której ludzie są ustawiani na podstawie kolejności przybycia.
Operacja wstawiania kolejki nazywana jest enqueue, a usuwanie/usuwanie elementu z początku kolejki to dequeuing.
Związane z: Przewodnik dla początkujących dotyczący zrozumienia kolejek i kolejek priorytetowych
Kolejki priorytetowe są integralną aplikacją kolejek w wielu ważnych aplikacjach, takich jak planowanie procesora. W kolejce priorytetowej elementy są uporządkowane według ich priorytetu, a nie kolejności przybycia.
6. hałdy

Sterty to rodzaj drzewa binarnego, w którym węzły są ułożone w porządku rosnącym lub malejącym. W min stercie wartość klucza rodzica jest równa lub mniejsza niż jego dzieci, a węzeł główny zawiera minimalną wartość całej sterty.
Podobnie węzeł główny Max Heap zawiera maksymalną wartość klucza sterty; musisz zachować min/max właściwość sterty w całej stercie.
Związane z: Stosy kontra Stosy: co je wyróżnia?
Hałdy mają wiele zastosowań ze względu na ich bardzo wydajny charakter; przede wszystkim kolejki priorytetowe są często implementowane przez sterty. Są również podstawowym elementem algorytmów sortowania sterty.
Poznaj struktury danych
Struktury danych mogą początkowo wydawać się wstrząsające, ale poświęć wystarczająco dużo czasu, a okaże się, że są łatwe.
Są istotną częścią programowania i prawie każdy projekt będzie wymagał ich użycia. Wiedza o tym, jaka struktura danych jest idealna dla danego scenariusza, ma kluczowe znaczenie.
Algorytmy te są niezbędne dla przepływu pracy każdego programisty.
Czytaj dalej
- Programowanie
- Analiza danych
- Wskazówki dotyczące kodowania

Fahad jest pisarzem w MakeUseOf i obecnie studiuje informatykę. Jako zapalony pisarz technologii dba o to, by był na bieżąco z najnowszą technologią. Szczególnie interesuje się piłką nożną i technologią.
Zapisz się do naszego newslettera
Dołącz do naszego newslettera, aby otrzymywać porady techniczne, recenzje, bezpłatne e-booki i ekskluzywne oferty!
Kliknij tutaj, aby zasubskrybować

