Reklama
Code 42, firma odpowiedzialna za CrashPlan, postanowiła całkowicie porzuć użytkowników domowych CrashPlan Shutters Cloud Backup dla użytkowników domowychCode42, firma stojąca za CrashPlan, ogłosiła, że porzuca użytkowników domowych. CrashPlan for Home zostaje zabity, a Code42 skupia się całkowicie na klientach korporacyjnych i biznesowych. Czytaj więcej . Ich bardzo konkurencyjne ceny sprawiły, że ich rozwiązanie do tworzenia kopii zapasowych było pokusą dla osób o dużych potrzebach tworzenia kopii zapasowych. Chociaż ich niedotrzymanie obietnic mogło zasiać ziarno nieufności, istnieją inni dostawcy chmury. Ale któremu dostawcy ufa archiwum memów?
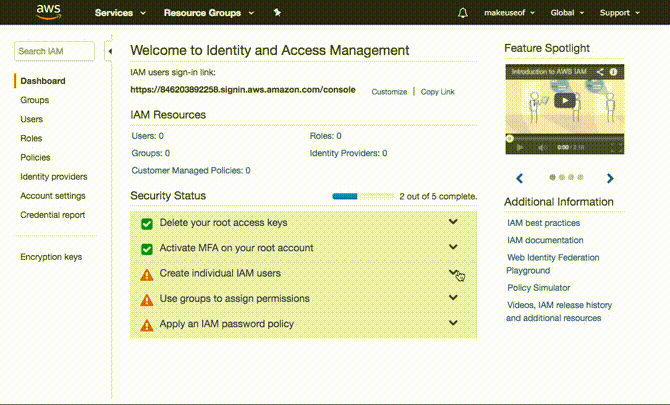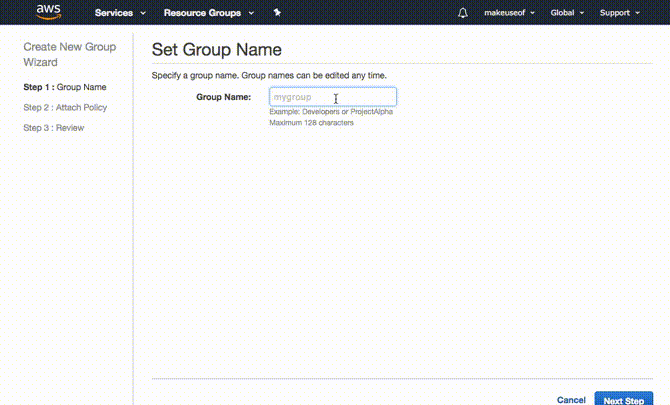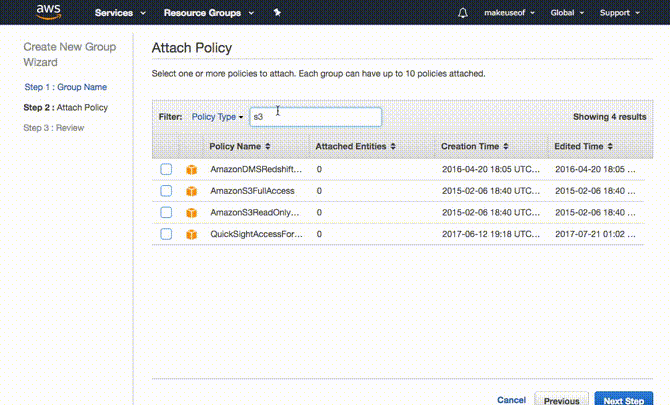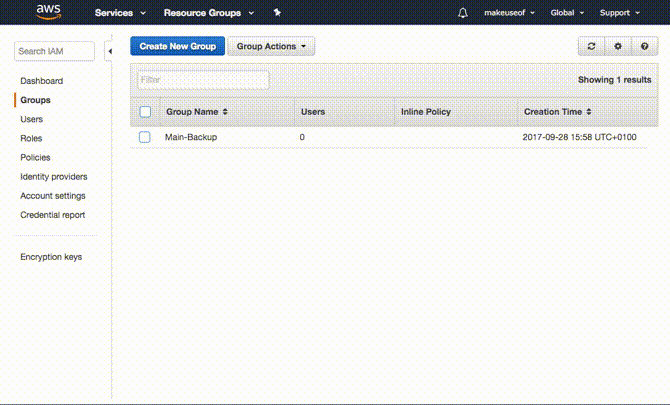
Obecnie światowym liderem w dziedzinie przetwarzania w chmurze jest Amazon Web Services (AWS). Krzywa uczenia się dla AWS może wydawać się stroma, ale w rzeczywistości jest prosta. Dowiedzmy się, jak skorzystać z wiodącej na świecie platformy chmurowej.
Proste rozwiązanie do przechowywania
Proste rozwiązanie pamięci masowej, powszechnie określane jako S3, jest gigantycznym rozwiązaniem firmy Amazon w zakresie pamięci masowej. Niektóre znaczące firmy korzystające z S3 to Tumblr, Netflix, SmugMug i oczywiście Amazon.com. Jeśli twoja szczęka jest nadal przymocowana do twarzy, AWS gwarantuje 99,9999999999999 procent wytrzymałości dla jej standardowej opcji i maksymalny rozmiar pliku (dowolnego pojedynczego pliku) pięciu terabajtów (5 TB). S3 to magazyn obiektów, co oznacza, że nie jest przeznaczony do instalowania i uruchamiania systemu operacyjnego, ale jest doskonale dostosowany do tworzenia kopii zapasowych.
Poziomy i ceny
Jak dotąd jest to najbardziej skomplikowana część S3. Ceny różnią się w zależności od regionu, aw naszym przykładzie zastosowano aktualne ceny dla regionu USA (Północnej Wirginii). Spójrz na ten stół:

S3 składa się z czterech klas pamięci. Standard oczywiście jest to standardowa opcja. Rzadko dostępny ogólnie jest tańszy do przechowywania danych, ale jest droższy do wejścia i wyjścia z danych. Zredukowana redundancja jest zwykle używany do danych, które można zregenerować w przypadku utraty, np. miniatury obrazów. Lodowiec służy do przechowywania archiwów, ponieważ jest to najtańszy sposób przechowywania. Jednak pobranie pliku z Glacier zajmie od trzech do pięciu godzin. Dzięki lodowcom lub chłodniom możesz uzyskać niższe koszty na gigabajt, ale zwiększone koszty użytkowania. Dzięki temu chłodnie lepiej nadają się do archiwizacji i odzyskiwania po awarii. Firmy na ogół korzystają z kombinacji wszystkich klas, aby dodatkowo obniżyć koszty.
Najlepsze w każdej kategorii są oznaczone kolorem niebieskim. Trwałość to prawdopodobieństwo, że plik zostanie utracony. Bar Reduced Redundancy, Amazon będzie musiał ponieść katastrofalną utratę w dwóch centrach danych, zanim dane zostaną utracone. Zasadniczo AWS będzie przechowywać twoje dane w wielu obiektach ze wszystkimi klasami oprócz klasy o zmniejszonej redundancji. Dostępność to, jak mało prawdopodobne jest przestoje. Resztę łatwiej przedstawić na przykładzie.
Przykładowe użycie
Nasz przypadek użycia jest następujący.
Chcę przechowywać w S3 Standard dziesięć plików o łącznej wielkości jednego gigabajta (1 GB). Przesyłanie plików lub Położyć poniesie żądanie w wysokości 0,005 USD i 0,039 USD za całość miejsca. Oznacza to, że w pierwszym miesiącu zostanie naliczona opłata w wysokości około 4,5 centów (0,044 USD) i nieco poniżej 4 centów (0,039 USD) za późniejsze zaparkowanie danych.
Dlaczego istnieje tak skomplikowana struktura cenowa? Jest tak, ponieważ jest to płatne za to, czego używasz. Nigdy nie płacisz za nic, z czego nie korzystasz. Jeśli myślisz o dużej firmie, oferuje to wszystkie zalety posiadania światowej klasy rozwiązania do przechowywania, przy jednoczesnym ograniczeniu kosztów do absolutnego minimum. Amazon zapewnia również Prosty kalkulator miesięczny który znajdziesz tutaj, dzięki czemu możesz wyświetlać swoje miesięczne wydatki. Na szczęście oferują również bezpłatny poziom, na który możesz się zapisać tutaj, dzięki czemu możesz wypróbować ich usługi przez okres do 12 miesięcy. Podobnie jak w przypadku wszystkiego nowego, gdy zaczniesz go używać, staje się on bardziej wygodny i zrozumiały.
Konsola
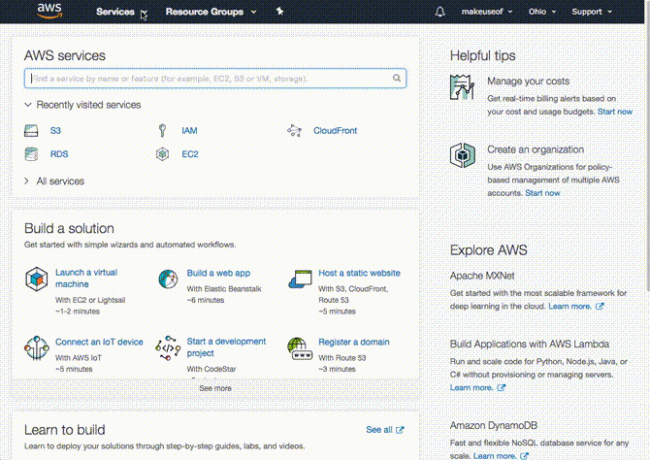
Bezpłatna warstwa AWS pozwala wypróbować wszystkie ich usługi do pewnego roku przez cały rok. W ramach bezpłatnej warstwy S3 zapewnia 5 GB przestrzeni dyskowej, 20 000 pobrań i 2000 pozycji. Powinno to zapewnić wystarczającą przestrzeń do przetestowania AWS i zdecydować, czy pasuje do twoich wymagań. Rejestracja w AWS prowadzi przez kilka kroków. Do weryfikacji potrzebna będzie ważna karta kredytowa lub debetowa oraz telefon. Po uruchomieniu konsoli zarządzania zostaniesz przywitany na pulpicie nawigacyjnym AWS.
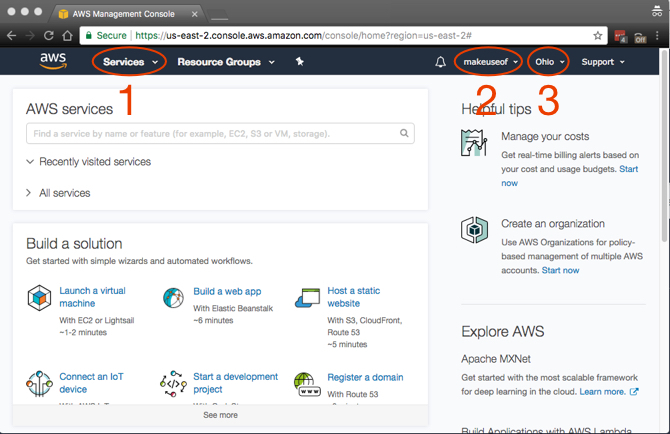
Na pierwszy rzut oka może się wydawać, że jest bardzo dużo do zrobienia, a to dlatego, że tak jest. Główne elementy, do których będziesz uzyskiwać dostęp, które są opatrzone adnotacjami na zrzucie ekranu, to:
- Usługi: Niespodzianka, niespodzianka Tutaj znajdziesz wszystkie usługi AWS.
- Konto: Aby uzyskać dostęp do swojego profilu i fakturowania.
- Region: To region AWS, w którym pracujesz.
Ponieważ chcesz mieć najniższe opóźnienia między komputerem (komputerami) a AWS, wybierz region najbliższy tobie. Niektóre regiony nie mają wszystkich usług AWS, ale są one wdrażane na bieżąco. Na szczęście dla nas S3 jest dostępny we wszystkich regionach!
S3 Security
Przed kontynuowaniem pierwszą pracą jest zabezpieczenie konta. Kliknij Usługi> Bezpieczeństwo, tożsamość i zgodność> IAM. W ramach tego procesu udzielimy również niezbędnych uprawnień na Twoim komputerze, abyś mógł bezpiecznie tworzyć kopie zapasowe i przywracać dane.
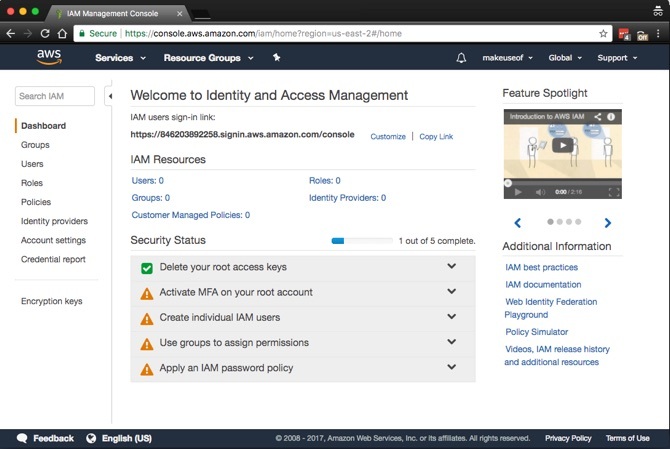
To prosty pięciostopniowy proces. Ze zrzutu ekranu zauważysz, że MFA można aktywować na swoim koncie. Chociaż uwierzytelnianie wieloskładnikowe (MFA), znane również jako uwierzytelnianie dwuskładnikowe (2FA) Jak zabezpieczyć system Ubuntu w systemie Linux za pomocą uwierzytelniania dwuskładnikowegoChcesz mieć dodatkową warstwę bezpieczeństwa podczas logowania do systemu Linux? Dzięki Google Authenticator można dodać uwierzytelnianie dwuskładnikowe do komputera z systemem Ubuntu (i innymi systemami operacyjnymi Linux). Czytaj więcej , nie jest wymagane, jest wysoce zalecane. Krótko mówiąc, wymaga połączenia nazwy użytkownika i hasła oraz kodu na urządzeniu mobilnym. Możesz uzyskać kompatybilne fizyczne urządzenie MFA lub skorzystać z aplikacji takiej jak Google Authenticator. Udaj się do albo Sklep z aplikacjami albo Sklep Play aby pobrać aplikację Google Authenticator.
Korzystanie z opcjonalnego uwierzytelniania wieloskładnikowego
Rozszerzać Aktywuj MFA na swoim koncie root i kliknij Zarządzaj MSZ. Upewnić się Wirtualne urządzenie MFA jest zaznaczone i kliknij Następny krok.
Otwórz Google Authenticator na swoim urządzeniu i zeskanuj kod kreskowy wyświetlany na ekranie. Wpisz kod autoryzacyjny w Kod autoryzacji 1 i poczekaj, aż kod odświeży się w Google Authenticator. Wyświetlenie następnego kodu zajmuje około 30 sekund. Wpisz nowy kod w Kod autoryzacji 2 pudełko z Google Authenticator. Teraz kliknij Aktywuj Virtual MFA przycisk. Po odświeżeniu ekranu Aktywacja MSZ będzie oznaczona zielonym ptaszkiem.
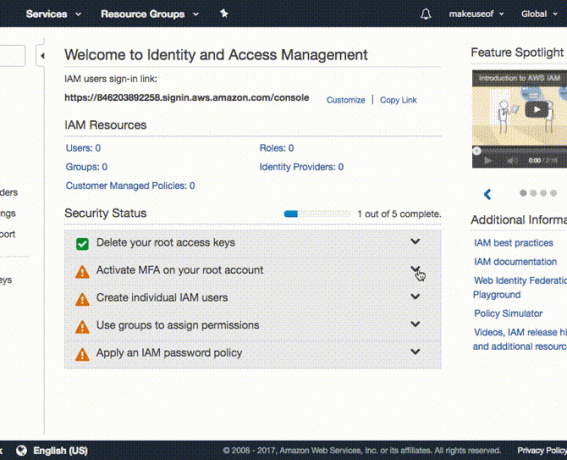
Powinieneś teraz aktywować MFA na swoim koncie i połączyć Google Authenticator z AWS. Przy następnym logowaniu do konsoli AWS wpisz swoją nazwę użytkownika i hasło w normalny sposób. AWS wyświetli monit o podanie kodu MFA. Zostanie to uzyskane z aplikacji Google Authenticator, podobnie jak w poprzednim kroku.
Grupy i uprawnienia
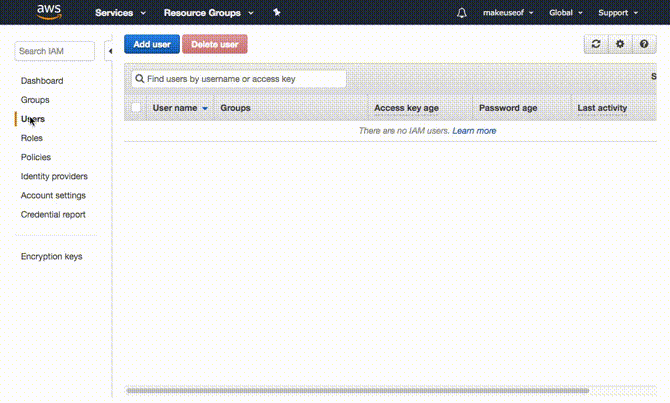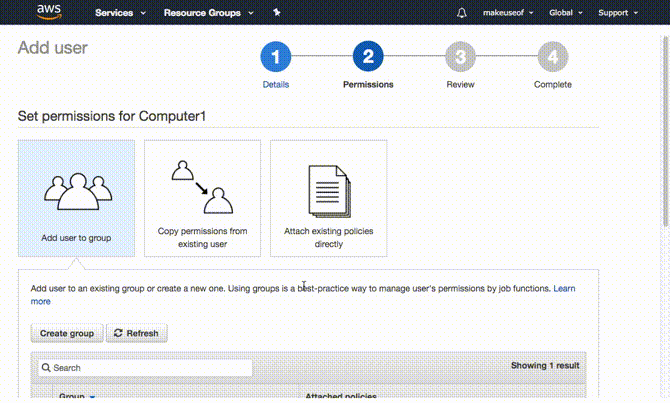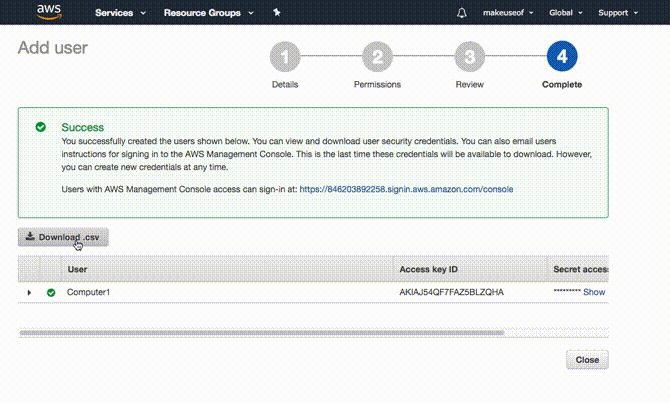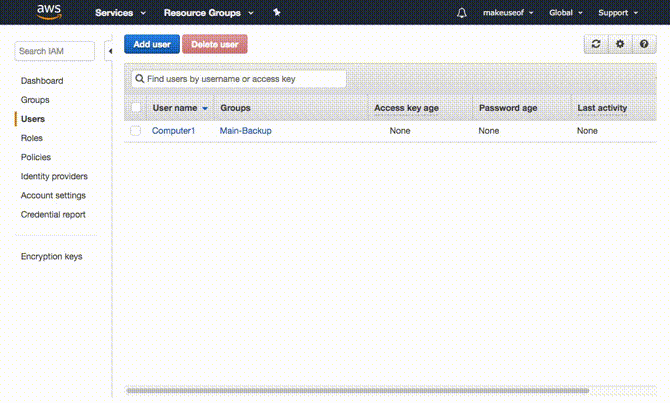
Czas zdecydować, jaki poziom dostępu będzie mieć Twój komputer do AWS. Najłatwiejszym i najbezpieczniejszym sposobem będzie utworzenie Grupa i a użytkownik dla komputera, którego kopię zapasową chcesz wykonać. Następnie udziel dostęp lub dodaj pozwolenie dla tej grupy na dostęp tylko do S3. Takie podejście ma wiele zalet. Poświadczenia podane tej grupie są ograniczone do S3 i nie można ich użyć do uzyskania dostępu do innych usług AWS. Dodatkowo, w niefortunnym przypadku, gdy Twoje dane uwierzytelniające zostały ujawnione, wystarczy usunąć dostęp do grupy, a Twoje konto AWS będzie bezpieczne.
Właściwie bardziej sensowne jest utworzenie grupy jako pierwszej. Aby to zrobić, rozwiń Twórz indywidualnych użytkowników IAM i kliknij Zarządzaj użytkownikami. Kliknij Grupy z panelu po lewej, a następnie Stwórz Nową Grupę. Wybierz nazwę swojej grupy i kliknij Następny krok. Teraz dołączymy pozwolenie lub zasady dla tej grupy. Ponieważ chcesz, aby ta grupa miała dostęp tylko do S3, filtruj listę, wpisując S3 w filtrze. Upewnij się, że AmazonS3FullAccess jest zaznaczone i kliknij Następny krok w końcu następuje Stworzyć grupę.
Utwórz użytkownika
Teraz musisz tylko utworzyć użytkownika i dodać go do utworzonej grupy. Wybierz Użytkownicy z panelu po lewej stronie i kliknij Dodaj użytkownika. Wybierz dowolną nazwę użytkownika, którą chcesz, w obszarze dostępu upewnij się Dostęp programowy jest zaznaczone i kliknij Dalej: Uprawnienia. Na następnej stronie wybierz utworzoną grupę i kliknij Dalej: Recenzja. AWS potwierdzi, że dodajesz tego użytkownika do wybranej grupy i potwierdzi przyznanie uprawnień. Kliknij Stwórz użytkownika aby przejść do następnej strony.
Zobaczysz teraz Identyfikator klucza dostępu i a Tajny klucz dostępu. Są one generowane samodzielnie i wyświetlane tylko raz. Możesz je skopiować i wkleić w bezpiecznej lokalizacji lub kliknąć Pobierz .csv który pobierze arkusz kalkulacyjny zawierający te szczegóły. Jest to odpowiednik nazwy użytkownika i hasła, których komputer będzie używał do uzyskania dostępu do S3.
Warto zauważyć, że należy traktować je z najwyższym poziomem bezpieczeństwa. W przypadku zgubienia tajnego klucza dostępu nie ma możliwości jego odzyskania. Musisz wrócić do konsoli AWS i wygenerować nową.
Twój pierwszy wiaderko
Nadszedł czas, aby stworzyć miejsce dla swoich danych. S3 ma sklepy o nazwie wiadra. Każda nazwa wiadra musi być globalnie unikalna, co oznacza, że kiedy utworzysz wiadro, będziesz jedynym na świecie o tej nazwie. Każde wiadro może mieć własny zestaw reguł konfiguracji. Możesz mieć wersjonowanie włączone w segmentach, aby zachować kopie aktualizowanych plików, aby można było przywrócić poprzednie wersje plików. Istnieją również opcje dla replikacja między regionami dzięki czemu możesz dodatkowo wykonać kopię zapasową danych w innym regionie w innym kraju.
Możesz dostać się do S3, przechodząc do Usługi> Przechowywanie> S3. Utworzenie wiadra jest tak proste, jak kliknięcie przycisku Utwórz wiadro przycisk. Po wybraniu globalnie unikalnej nazwy (tylko małe litery) wybierz region, w którym ma mieszkać wiadro. Kliknięcie Stwórz przycisk w końcu da ci pierwsze wiadro.
Linia poleceń to życie
Gdyby linia poleceń jest twoją bronią z wyboru 4 sposoby uczenia się poleceń terminalowych w systemie LinuxJeśli chcesz zostać prawdziwym mistrzem Linuksa, dobrym pomysłem jest posiadanie wiedzy na temat terminali. Oto metody, których możesz użyć, aby zacząć uczyć siebie. Czytaj więcej , możesz uzyskać dostęp do nowo utworzonego segmentu S3 za pomocą s3cmd które możesz pobierz stąd. Po wybraniu najnowszej wersji pobierz archiwum zip do wybranego folderu. Obecna najnowsza wersja to 2.0.0, której będziesz używać w naszym przykładzie. Aby rozpakować i zainstalować s3cmd, otwórz okno terminala i wpisz:
sudo apt install python-setuptools. rozpakuj s3cmd-2.0.0. cd s3cmd-2.0.0. sudo python setup.py installs3cmd jest teraz zainstalowany w twoim systemie i jest gotowy do skonfigurowania i połączenia z twoim kontem AWS. Pamiętaj, aby mieć swój Identyfikator klucza dostępu i Tajny klucz dostępu do przekazania od momentu utworzenia użytkownika. Zacznij od wpisania:
s3cmd --configureZostaniesz poproszony o podanie kilku szczegółów. Po pierwsze, zostaniesz poproszony o wprowadzenie identyfikatora klucza dostępu, a następnie tajnego klucza dostępu. Wszystkie pozostałe ustawienia można pozostawić jako domyślne, naciskając tylko klawisz Enter, z wyjątkiem Szyfrowanie oprawa. Tutaj możesz wybrać hasło, aby dane wysyłane i wysyłane z S3 były szyfrowane. Zapobiegnie to mężczyzna w środku ataku Pięć internetowych narzędzi szyfrujących do ochrony Twojej prywatności Czytaj więcej lub ktoś przechwytujący ruch internetowy.
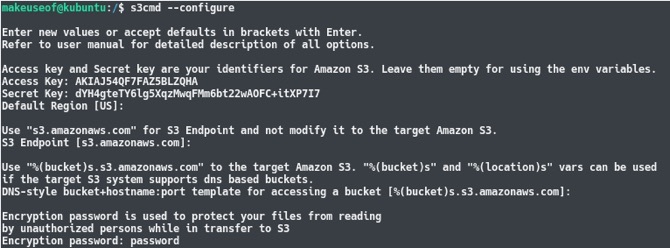
Pod koniec procesu konfiguracji s3cmd przeprowadzi test, aby upewnić się, że wszystkie ustawienia działają i że możesz pomyślnie połączyć się ze swoim kontem AWS. Po wykonaniu tej czynności będziesz mógł wpisać kilka poleceń, takich jak:
s3cmd lsSpowoduje to wyświetlenie wszystkich wiader na koncie S3. Jak pokazuje poniższy zrzut ekranu, utworzone wiadro jest widoczne!

Synchronizacja za pomocą wiersza polecenia
Polecenie synchronizacji dla s3cmd jest niezwykle wszechstronne. Jest bardzo podobny do normalnego kopiowania pliku w systemie Linux i wygląda trochę tak:
s3cmd sync [LOCAL PATH] [REMOTE PATH] [PARAMETERS]Przetestuj jego użycie za pomocą prostej synchronizacji. Najpierw utwórz dwa pliki tekstowe za pomocą dotknąć polecenie, a następnie użyj synchronizacja polecenie, aby wysłać utworzone pliki do utworzonego wcześniej segmentu. Odśwież wiadro S3; zauważysz, że pliki zostały rzeczywiście wysłane do S3! Upewnij się, że zastąpiłeś ścieżkę lokalną ścieżką lokalną na komputerze, a także zmieniłeś ścieżkę zdalną na nazwę segmentu. Aby osiągnąć ten typ:
dotknij plik 1.txt. dotknij pliku 2.txt. s3cmd sync ~ / Backup s3: // makeuseof-backup
The synchronizacja polecenie, jak wspomniano, najpierw sprawdza i porównuje oba katalogi. Jeśli plik nie istnieje w S3, prześle go. Co więcej, jeśli plik istnieje, sprawdzi, czy został zaktualizowany przed skopiowaniem do S3. Jeśli chcesz również usunąć pliki, które zostały usunięte lokalnie, możesz uruchomić polecenie za pomocą –Delete-remove parametr. Przetestuj to, najpierw usuwając jeden z utworzonych przez nas plików tekstowych, a następnie polecenie synchronizacji z dodatkowym parametrem. Jeśli następnie odświeżysz wiadro S3, usunięty plik zostanie teraz usunięty z S3! Aby spróbować, wpisz:
rm plik-1.txt. s3cmd sync ~ / Backup s3: // makeuseof-backup - usuń usunięty
Na pierwszy rzut oka widać, jak przekonująca jest ta metoda. Jeśli chcesz wykonać kopię zapasową czegoś na koncie AWS, możesz dodaj polecenie synchronizacji do zadania cron Jak planować zadania w systemie Linux za pomocą Cron i CrontabMożliwość automatyzacji zadań jest jedną z tych futurystycznych technologii, które już tu są. Każdy użytkownik systemu Linux może korzystać z harmonogramu zadań systemowych i zadań użytkownika, dzięki cron, łatwej w obsłudze usłudze w tle. Czytaj więcej i automatycznie wykonaj kopię zapasową komputera na S3.
Alternatywa GUI
Jeśli nie masz wiersza poleceń, istnieje graficzny interfejs użytkownika (GUI) alternatywny dla s3cmd: Cloud Explorer. Chociaż nie ma bardzo nowoczesnego interfejsu, ma kilka interesujących funkcji. Jak na ironię najłatwiejszą metodą uzyskania najnowszej wersji jest skorzystanie z wiersza polecenia. Po otwarciu okna terminala z folderem, w którym chcesz go zainstalować, wpisz:
sudo apt -y install Jak korzystać z APT i pożegnać się z APT-GET w Debianie i UbuntuLinux jest w stanie ciągłej ewolucji; główne zmiany są czasami łatwo przeoczone. Chociaż niektóre ulepszenia mogą być zaskakujące, niektóre po prostu mają sens: sprawdź te zmiany apt-get i zobacz, co myślisz. Czytaj więcej openjdk-8-head ant ant git. klon gita https://github.com/rusher81572/cloudExplorer.git. cd cloudExplorer. Mrówka. cd dist. java -jar CloudExplorer.jarPo uruchomieniu interfejsu niektóre z wymaganych pól powinny już wydawać się znajome. Aby załadować konto AWS, wprowadź swój klucz dostępu, tajny klucz, podaj nazwę konta i kliknij Zapisać.
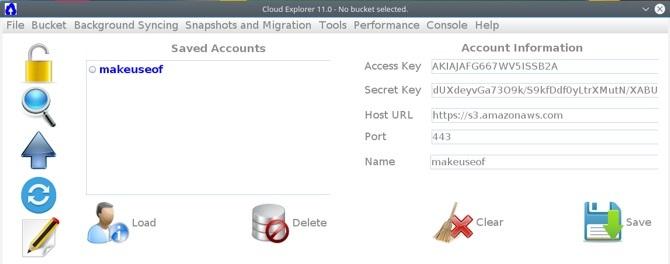
Możesz teraz kliknąć zapisany profil i uzyskać dostęp do wiadra.
Odkrywanie Eksploratora
Rzut oka na interfejs zobaczysz następujące elementy:
- Wyloguj
- Przeglądaj i szukaj
- Prześlij pliki
- Synchronizacja
- Edytor tekstu
- Panel z listą twoich wiader
- Panel do nawigacji po wybranym segmencie
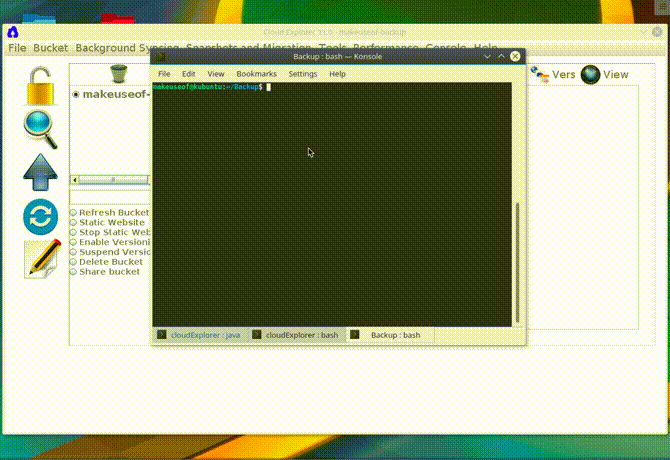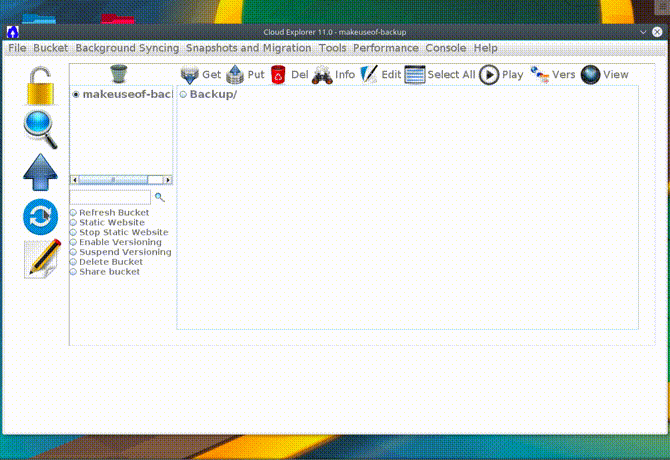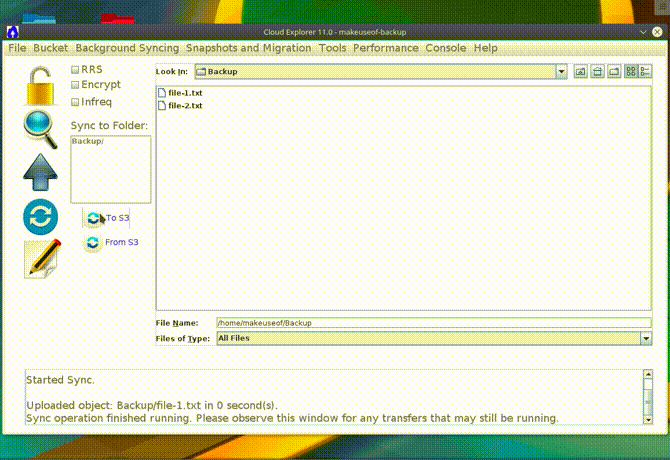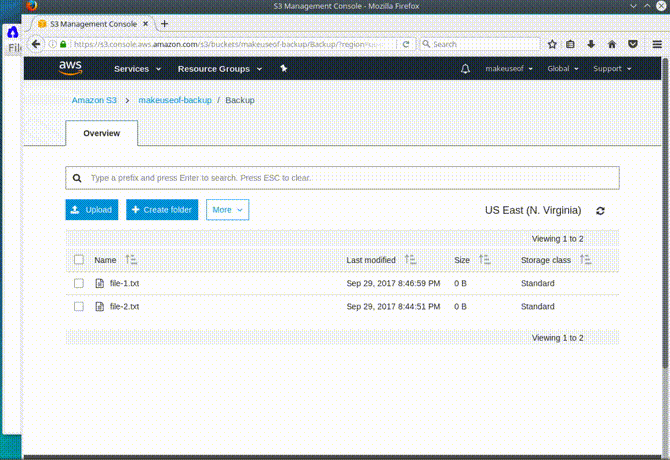
Konfigurowanie funkcji synchronizacji Cloud Explorer jest podobne do s3cmd. Najpierw utwórz plik, który nie istnieje w segmencie S3. Następnie kliknij Synchronizacja przycisk w Eksploratorze chmury i przejdź do folderu, który chcesz zsynchronizować z S3. Kliknięcie na Do S3 sprawdzi różnice między folderem na komputerze lokalnym a folderem z S3 i prześle wszelkie znalezione różnice.
Gdy odświeżysz segment S3 w przeglądarce, zauważysz, że nowy plik został wysłany do S3. Niestety funkcja synchronizacji w Eksploratorze chmury nie obsługuje plików usuniętych na komputerze lokalnym. Więc jeśli usuniesz plik lokalnie, pozostanie on w S3. Należy o tym pamiętać.
Użytkownicy domowi mogą korzystać z firmowego przechowywania danych w chmurze
Chociaż AWS jest rozwiązaniem zaprojektowanym dla firm do korzystania z chmury, nie ma powodu, dla którego użytkownicy domowi nie powinni brać udziału w akcji. Korzystanie z wiodącej na świecie platformy chmurowej ma wiele zalet. Nigdy nie musisz się martwić o aktualizację sprzętu lub płacenie za nic, czego nie używasz. Innym interesującym faktem jest to, że AWS ma większy udział w rynku niż łącznie 10 kolejnych dostawców. Wskazuje to, jak daleko są do przodu. Konfiguracja AWS jako rozwiązania zapasowego wymaga:
- Tworzenie konta.
- Zabezpieczanie konta w MFA.
- Tworzenie grupy i przypisywanie uprawnień do grupy.
- Dodanie użytkownika do grupy.
- Tworzenie pierwszego wiadra.
- Używanie wiersza poleceń do synchronizacji z S3.
- Alternatywa GUI dla S3.
Czy obecnie używasz AWS do czegoś? Którego dostawcy kopii zapasowych w chmurze używasz obecnie? Jakich funkcji szukasz przy wyborze dostawcy kopii zapasowych? Daj nam znać w komentarzach poniżej!
Yusuf chce żyć w świecie pełnym innowacyjnych firm, smartfonów dołączonych do ciemnej palonej kawy i komputerów z hydrofobowymi polami siłowymi, które dodatkowo odpychają kurz. Jako analityk biznesowy i absolwent Politechniki w Durbanie, z ponad 10-letnim doświadczeniem w szybko rozwijającej się branży technologicznej, lubi być środkowym człowiekiem między…