Reklama
Możemy teraz rozmawiać z prawie wszystkimi naszymi gadżetami, ale dokładnie jak to działa? Kiedy pytasz „Co to za piosenka?” lub powiedz „Zadzwoń do mamy”, dzieje się cud współczesnej technologii. I choć wydaje się, że jest w czołówce, pomysł rozmawiania z urządzeniami sięga dziesięcioleci - prawie tak daleko jak plecaki odrzutowe w science fiction!
Obecnie większość uwagi poświęcanej komputerowemu sterowaniu głosem skupia się na smartfonach. Apple, Amazon, Microsoft i Google znajdują się na szczycie łańcucha, z których każdy oferuje własny sposób komunikowania się z elektroniką. Wiesz, kim oni są: Siri, Alexa, Cortana i bezimienne „Ok, Google”. Co rodzi duże pytanie…
W jaki sposób urządzenie bierze wypowiedziane słowa i zamienia je w polecenia, które może zrozumieć? Zasadniczo sprowadza się do dopasowywania wzorców i przewidywania na podstawie tych wzorców. Mówiąc dokładniej, rozpoznawanie głosu jest złożonym zadaniem Modelowanie akustyczne i Modelowanie języka.
Modelowanie akustyczne: przebiegi i telefony
Modelowanie akustyczne to proces pobierania fali mowy i analizowania jej za pomocą modeli statystycznych. Najczęstszą metodą jest to Ukryte modelowanie Markowa, który jest używany w tzw modelowanie wymowy rozbicie mowy na części składowe zwane telefonami (nie mylić z rzeczywistymi urządzeniami telefonicznymi). Microsoft od wielu lat jest wiodącym badaczem w tej dziedzinie.
Ukryte modelowanie Markowa: stany prawdopodobieństwa
Ukryte modelowanie Markowa to predykcyjny model matematyczny, w którym bieżący stan określa się poprzez analizę wyniku. Wikipedia ma świetny przykład z wykorzystaniem dwóch przyjaciół.
Wyobraź sobie dwóch przyjaciół - lokalnego przyjaciela i zdalnego przyjaciela - mieszkających w różnych miastach. Lokalny przyjaciel chce dowiedzieć się, jaka jest pogoda tam, gdzie mieszka zdalny przyjaciel, ale zdalny przyjaciel chce tylko rozmawiać o tym, co zrobił tego dnia: chodzić, robić zakupy lub sprzątać. Prawdopodobieństwo każdej aktywności w zależności od pogody w ciągu dnia.
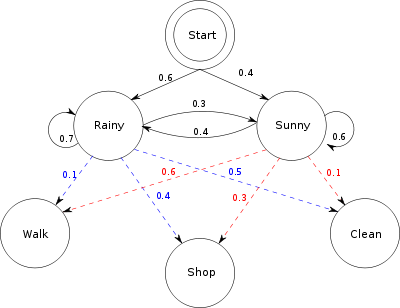
Udawaj, że to jedyne dostępne informacje. Dzięki niemu lokalny przyjaciel może znaleźć trendy w zmianie pogody z dnia na dzień i korzystając z tych trendów, ona może zacząć zgadywać, jaka będzie dzisiejsza pogoda na podstawie wczorajszej aktywności przyjaciółki. (Możesz zobaczyć schemat systemu powyżej.)
Jeśli potrzebujesz bardziej złożonego przykładu, sprawdź ten przykład na Matlabie. W rozpoznawaniu głosu model ten zasadniczo porównuje każdą część przebiegu z tym, co jest przedtem, a co później, oraz ze słownikiem przebiegów, aby dowiedzieć się, co zostało powiedziane.
Zasadniczo, jeśli wydasz „th” dźwięk, sprawdzi on ten dźwięk pod kątem najbardziej prawdopodobnych dźwięków, które zwykle pojawiają się przed nim i po nim. Może to oznacza sprawdzanie dźwięku „e”, dźwięku „at” i tak dalej. Kiedy wzór pasuje poprawnie, ma całe twoje słowo. To nadmierne uproszczenie, ale widać Całe wyjaśnienie Microsoftu tutaj.
Modelowanie języka: więcej niż dźwięk
Modelowanie akustyczne pomaga w zrozumieniu twojego komputera, ale co z homonimami i regionalnymi odmianami wymowy? Właśnie tutaj wchodzi w grę Modelowanie Językowe. Google przeprowadził wiele badań w tej dziedzinie, głównie poprzez wykorzystanie Modelowanie N-gramowe.
Kiedy Google próbuje zrozumieć twoją mowę, robi to na podstawie modeli pochodzących z ogromnego banku wyszukiwania głosowego i transkrypcji na YouTube. Wszystkie te przezabawne napisy wideo pomogły Google rozwinąć ich słowniki. Wykorzystali także zmarłych GOOG-411 zbierać informacje o tym, jak ludzie mówią.

Cała ta kolekcja językowa stworzyła szeroką gamę wymowy i dialektów, co stworzyło solidny słownik słów i ich brzmienia. Pozwala to na dopasowania, które mają znacznie mniejszy poziom błędu niż dopasowanie brutalne oparte na surowych prawdopodobieństwach. Możesz przeczytać krótki artykuł opisując tutaj swoje metody.
Chociaż Google jest liderem w tej dziedzinie, opracowywane są inne modele matematyczne, w tym ciągła przestrzeń kosmiczna modele i modele języka pozycyjnego, które są bardziej zaawansowanymi technikami zrodzonymi z badań nad sztuczną inteligencją. Metody te opierają się na replikacji rozumowania, jakie robią ludzie podczas wzajemnego słuchania się. Są one znacznie bardziej zaawansowane zarówno pod względem technologii, jak i za nimi, ale także matematyki i programowania potrzebnego do mapowania tych modeli.
Modelowanie N-Gram: prawdopodobieństwo spotyka pamięć
Modelowanie N-gram działa w oparciu o prawdopodobieństwa, ale wykorzystuje istniejący słownik słów, aby utworzyć rozgałęzione drzewo możliwości, które jest następnie wygładzane ze względu na wydajność. W pewnym sensie oznacza to, że Modelowanie N-gram eliminuje wiele niepewności we wspomnianym Modelowaniu Ukrytym Markowa.
Jak wspomniano powyżej, siła tej metody wynika z posiadania dużego słownika słowa i stosowanie, nie tylko prymitywne odgłosy. Daje to programowi możliwość odróżnienia homofonów, takich jak „beat” i „burak”. Jest kontekstowy, co oznacza, że kiedy mówisz o wynikach z wczorajszej nocy, program nie pokazuje słów o barszczu.
Ale te modele nie są najlepsze dla języka, głównie z powodu problemów z prawdopodobieństwem słów w dłuższych frazach. Gdy dodajesz więcej słów do zdania, ten model zaczyna się trochę denerwować, ponieważ jest mało prawdopodobne, aby twoje wczesne słowa załadowały wszystko, co potrzebne do pełnej myśli.
Jest jednak prosty i łatwy do wdrożenia, dzięki czemu doskonale pasuje do firmy takiej jak Google, która lubi rzucać serwery na problemy obliczeniowe. Możesz przeczytać więcej na temat N-gram Modelieng na stronie uniwersytet Waszyngtońskilub możesz obejrzeć wykład w Coursera.
Krzyczy w chmurach: aplikacje i urządzenia
Każdy, kto używał Siri, zna frustrację związaną z wolnym połączeniem sieciowym. Wynika to z faktu, że polecenia do Siri są wysyłane przez sieć w celu odkodowania przez Apple. Cortana na telefon z systemem Windows wymaga również połączenia sieciowego do prawidłowego działania. W przeciwieństwie do tego Amazon Echo to tylko głośnik Bluetooth bez Internetu.
Skąd ta różnica? Ponieważ Siri i Cortana potrzebują wytrzymałych serwerów do dekodowania mowy. Czy można to zrobić na telefonie lub tablecie? Jasne, ale w ten sposób zabiłbyś swoją wydajność i żywotność baterii. Po prostu bardziej sensowne jest przeniesienie przetwarzania na dedykowane maszyny.
Pomyśl o tym w ten sposób: twoje polecenie to samochód utknięty w błocie. Prawdopodobnie mógłbyś sam go wypchnąć z wystarczającą ilością czasu i wysiłku, ale zajmie to godziny i sprawi, że będziesz wyczerpany. Zamiast tego dzwonisz po pomoc drogową, a oni wyciągają samochód w ciągu kilku minut. Minusem jest to, że musisz zadzwonić i czekać na nie, ale nadal jest to szybsze i mniej obciążające.
Modele stacjonarne, takie jak Nuance, zwykle używają zasobów lokalnych ze względu na mocniejszy sprzęt. W końcu, według słów Steve'a Jobsa, twój pulpit to ciężarówka. (Co sprawia, że to trochę głupie, że używa OS X serwery do jego przetwarzania.) Więc kiedy musisz przetwarzać język i głos, jest on już wystarczająco dobrze wyposażony, aby poradzić sobie z nim samodzielnie.
Z drugiej strony Android pozwala programistom na włączenie rozpoznawania mowy offline w swoich aplikacjach. Google lubi wyprzedzać technologię i możesz się założyć, że inne platformy zyskają tę umiejętność, gdy ich sprzęt będzie coraz potężniejszy. Nikt nie lubi, gdy słabe pokrycie lub zły odbiór lobotomizują swoje urządzenie.
Zacznij korzystać z poleceń głosowych już teraz
Teraz, gdy znasz podstawowe pojęcia, powinieneś bawić się różnymi urządzeniami. Wypróbuj nowy pisanie głosowe w Dokumentach Google Jak pisanie głosowe jest nową najlepszą funkcją Dokumentów GoogleW ostatnich latach rozpoznawanie głosu poprawiło się skokowo. Na początku tego tygodnia Google w końcu wprowadził pisanie głosowe w Dokumentach Google. Ale czy to jest dobre? Dowiedzmy Się! Czytaj więcej . Jak gdyby pakiet biurowy nie był jeszcze wystarczająco wydajny, sterowanie głosowe pozwala całkowicie dyktować i formatować dokumenty. Rozszerza to zaawansowaną technologię, którą już zaprojektowali dla Chrome i Androida.
Inne pomysły obejmują konfigurację Mac, aby korzystać z poleceń głosowych Jak korzystać z poleceń mowy na komputerze Mac Czytaj więcej i konfigurowanie twojego Amazon Echo z automatyczną kasą Jak Amazon Echo może uczynić Twój dom inteligentnym domemTechnologia inteligentnego domu jest wciąż w początkowej fazie, ale nowy produkt Amazon o nazwie „Echo” może pomóc we wprowadzeniu jej do głównego nurtu. Czytaj więcej . Żyj w przyszłości i rozmawiaj ze swoimi gadżetami - nawet jeśli zamawiasz więcej ręczników papierowych. Jeśli jesteś uzależniony od smartfona, mamy również samouczki dla Siri 8 rzeczy, których prawdopodobnie nie zdawałeś sobie sprawy z SiriSiri stała się jedną z najważniejszych funkcji iPhone'a, ale dla wielu osób nie zawsze jest najbardziej przydatna. Chociaż niektóre z nich wynikają z ograniczeń rozpoznawania głosu, dziwność korzystania z ... Czytaj więcej , Cortana 6 najfajniejszych rzeczy, które możesz kontrolować za pomocą Cortany w systemie Windows 10Cortana może pomóc Ci korzystać z zestawu głośnomówiącego w systemie Windows 10. Możesz pozwolić jej przeszukiwać twoje pliki i Internet, wykonywać obliczenia lub wyświetlać prognozę pogody. Tutaj omawiamy niektóre z jej fajniejszych umiejętności. Czytaj więcej , i Android OK, Google: 20 przydatnych rzeczy, które możesz powiedzieć na swój telefon z AndroidemAsystent Google może pomóc Ci wiele zrobić na telefonie. Oto cała masa podstawowych, ale przydatnych komend OK Google do wypróbowania. Czytaj więcej .
Jakie jest twoje ulubione użycie sterowania głosowego? Daj nam znać w komentarzach.
Kredyty obrazkowe: T-flex przez Shutterstock, Terencehonles za pośrednictwem Wikimedia Foundation, Stan Arizona, Cienpies Design via Shutterstock
Michael nie używał komputera Mac, kiedy byli skazani na zagładę, ale potrafi pisać w Applescript. Ukończył informatykę i angielski; od jakiegoś czasu pisze o Macu, iOS i grach wideo; i od ponad dekady jest małpą IT dnia, specjalizującą się w skryptach i wirtualizacji.


